 Thiago Bastos
Thiago BastosQCon London 2020 – Trends and Insights
Contents
QCon London 2020 was five weeks ago, but already it feels like another era. I went to London for the 3-day conference, gathered with thousands of people, went to restaurants and pubs, and a week later went into permanent self-quarantine in Munich due to the COVID-19 outbreak.
Looking back, everyone who attended the conference was incredibly lucky: only one speaker canceled, and after a week only two attendees (from the same company) reported coronavirus-like symptoms. Not bad for a conference of over 170 speakers and 1600 attendees! The QEII Centre is huge; hand sanitizers were everywhere and also handed out; and instead of the usual buffet meals, food was offered in bento boxes to avoid contamination.
QCon’s motto is Bleeding-edge for the Enterprise. It is a practitioner-driven conference focused on innovation in enterprise software development and targeted at senior engineers and architects. This was my first QCon—after attending GOTO Berlin in 2018 and CraftConf in 2019—and I was impressed. Here are my takeaways for this year’s event.

Enjoying the outside after a fire alarm went off and we had to evacuate the QEII Centre.
Microservices
Microservices are still going strong. They were neither hyped nor downplayed, and the talks were more mature—which is a sign that the technology has become more widely understood and may be past the “Trough of Disillusionment” in the Gartner hype cycle.
Microservices are now considered a late majority topic. Likewise, Domain-Driven Design (DDD) is still an essential tool for designing microservices, but a late majority topic. Now that “we know” how to find good boundaries for microservices, the focus seems to have shifted to three other areas: observability, developer experience and resilience engineering.
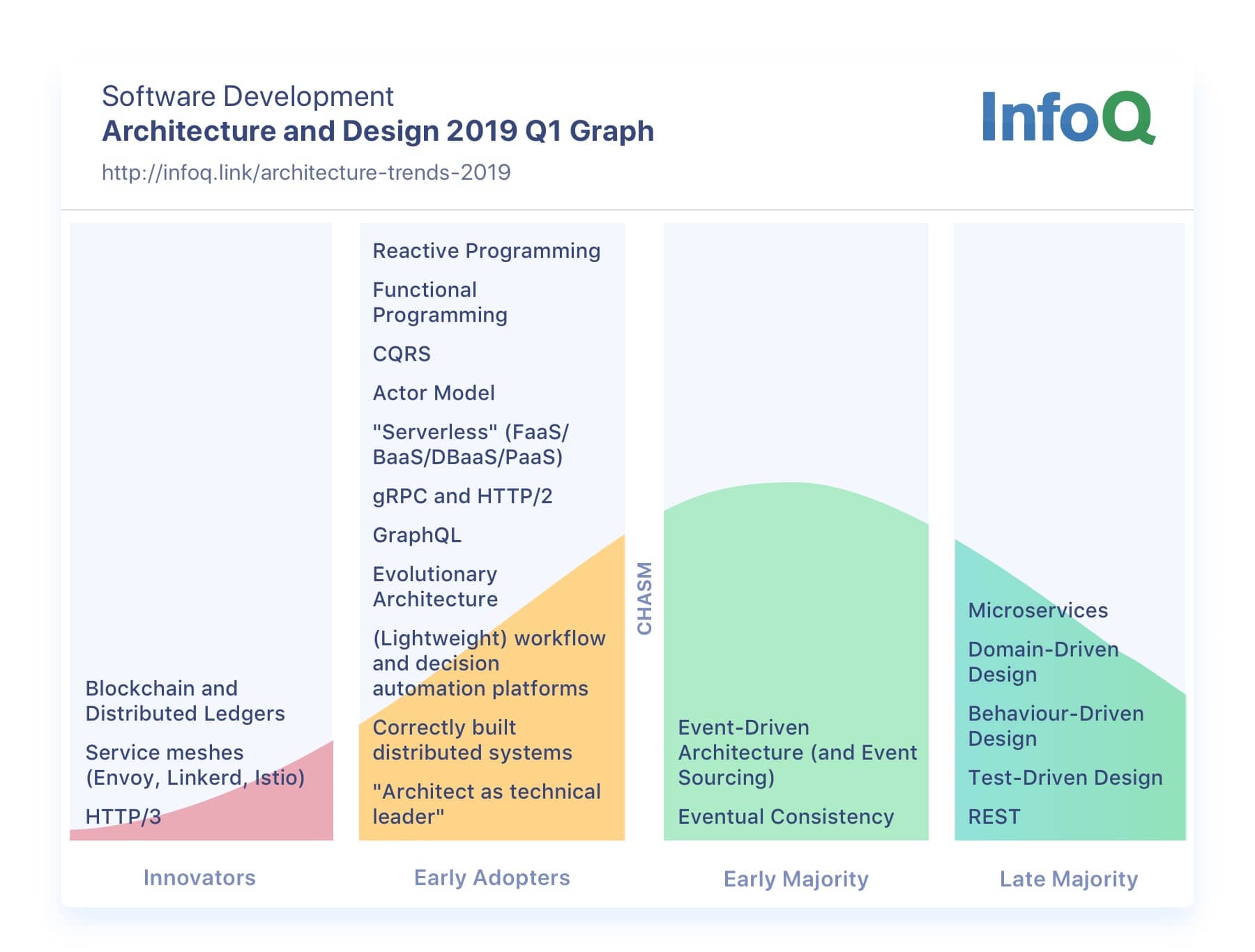
InfoQ – Architecture and Design Trends 2019 (2020 pending)
Observability
Observability is commonly defined in terms of its “three pillars”: Logs, Metrics, and Traces. Historically, we have used different tools for each pillar—e.g. Elasticsearch for log aggregation, Prometheus for metrics, and Jaeger for distributed tracing—which can be a pain if we need to correlate data from multiple sources in order to debug a system.
Observability is about bringing it all together into a single tool to gain a holistic understanding of our systems. For example, gathering logs, metrics and traces, and providing a consolidated visualization of all events with traces and metrics attached to them. Observability tools have virtually unlimited potential and most big platforms already offer AIOps and programmability as features.
Several monitoring platforms made the leap to full observability in recent years. Two of the most popular full-stack observability platforms are currently Datadog and New Relic (see comparison). Open-source solutions are still lagging behind, but Grafana recently announced that they want to become a full observability platform.
To reap the benefits of observability, we need to instrument our software to produce telemetry data. A happy development is that all observability platforms are embracing OpenTelemetry now, and the project has enough momentum to become a de facto standard this year. OpenTelemetry began its beta on March 30th and should be production-ready by the second half of 2020. The first release will support tracing and metrics only, with support for logging coming later.
Developer Experience
Developer Experience (DevEx), as described in this great talk by Daniel Bryant, is primarily about “reducing engineering friction” and “minimizing the distance between an idea and production”. It is a new buzzword for something that has been a concern since the dawn of software development, but gained renewed importance with the rise of DevOps and cloud-native architectures.
If we consider the four key metrics of software delivery performance, from the State of DevOps reports and Accelerate, three of them are directly related to DevEx: lead time, deployment frequency, and mean time to restore. And since this set of metrics is a strong indicator of high-performing teams, we can expect a strong correlation between DevEx and team performance.
DevOps performance is a function of throughput and stability, as captured by the four key metrics. Elite performers release many times per day; move from code committed to code deployed in less than a day; recover from outages in less than an hour; and revert less than 15% of changes due to failures. And just like in Lean manufacturing, it all boils down to eliminating waste (or friction).
If I had to synthesize the advice offered in the talks as five DevEx principles, these would be it:
- Accelerate feedback loops (minimize waiting time)
- Automate as much as possible (workflow tooling)
- Minimize cognitive load (observability, predictability, simplicity)
- Minimize context switching (WIP; loss of focus)
- Improve continuously (Kaizen)
Principles [1, 4, 5] coincide with Lean development. And the most interesting and often neglected principle is “minimizing cognitive load”. Architectural styles such as microservices and FaaS have helped us work more effectively at scale, but our ability to understand the complex distributed systems we are creating has fallen way behind. We need better tools for understandability, observability and debuggability.
Here is a list of more specific ways to improve DevEx:
- Use GitOps and declarative infrastructure.
- Automate your inner development loop with tools such as Telepresence and Skaffold
- Rethink your testing strategy using less test doubles and more tests in (pre)production.
- Implement observability and “observability UX” (simple, low-cognitive-load dashboards)
- Deploy with progressive delivery using a service mesh and Flagger.
- Build guide rails that “make it easy to do the right thing”, such as: tech radars, templates/scaffolding, frameworks and self-service platforms.
- And for mission-critical systems: use stronger guide rails.
- Test in preproduction and use progressive delivery to production.
- Invest heavily in observability, debuggability and “recreatability” of environments and data.
Resilience Engineering
It seems that some companies got a bit distracted with chaos engineering while their focus should have been on resilience engineering. Resilience is the end goal and there are a number of ways to it. Chaos engineering is great, but it is just the starting point for resilience. This was the theme of Nora Jones’ talk, “Rethinking How the Industry Approaches Chaos Engineering”.
“Resilience is not about reducing errors. It is about enhancing the positive capabilities of people and organizations that allow them to adapt effectively and safely under pressure.”
— Dekker, Woods, Cook
“The goal of Chaos Engineering isn’t to use or build tooling to stop issues or find vulnerabilities for us. The goal is to build a culture of resilience to the unexpected. If tools can help with this, excellent… but don’t forget the main goal of chaos as you’re building these tools.”
— Nora Jones
Another highly praised talk in Resilience Engineering was Dr. Laura Maguire’s “How Many Is Too Much? Exploring Costs of Coordination During Outages”, which covered helpful and harmful patterns of coordination in incident response practices. The video should be available on InfoQ soon.
Talk Highlights
Modern Banking in 1500 Microservices: Matt Heath and Suhail Pate, engineers at UK-based Monzo bank, explain how Monzo built their banking platform using over 1500 microservices since they started, in 2015. Their secret to managing complexity? Strong guide rails: all microservices are written in Go and follow a strict structure. They have custom tools and a lot of automation in their platform. They find it easy to hire and onboard developers and move them between teams.
Building a Composable Enterprise with APIs and Product Thinking: Paul Fremantle makes the point that APIs are digital products that require product management. He proposes a cell-based reference architecture for agile enterprises, and discusses several kinds of API marketplaces (internal, partner, closed group, aggregator) and API federation.
Developer Effectiveness: Optimizing Feedback loops: Tim Cochran, Technical Director for ThoughtWorks, clearly sells DevEx without ever using the term. He explains that companies that cannot improve on the four key metrics from Accelerate are usually missing an effective environment for developers. Bureaucratic processes, delays and manual steps add up and lead to “death by a thousand paper cuts”. He shows what both low and high effectiveness look like for things like: validating changes to a component; finding the root cause for a defect; becoming productive in a new team; and launching a new service in production. High-performing teams have more automated workflows and shorter feedback loops.
Tesla Virtual Power Plant: Colin Breck and Percy Link gave the first public talk ever about the Tesla VPP—now available online. The whole project is technologically impressive, down to their application platform. Batteries are modeled as stateful actors using Kafka, protobuf and Akka.
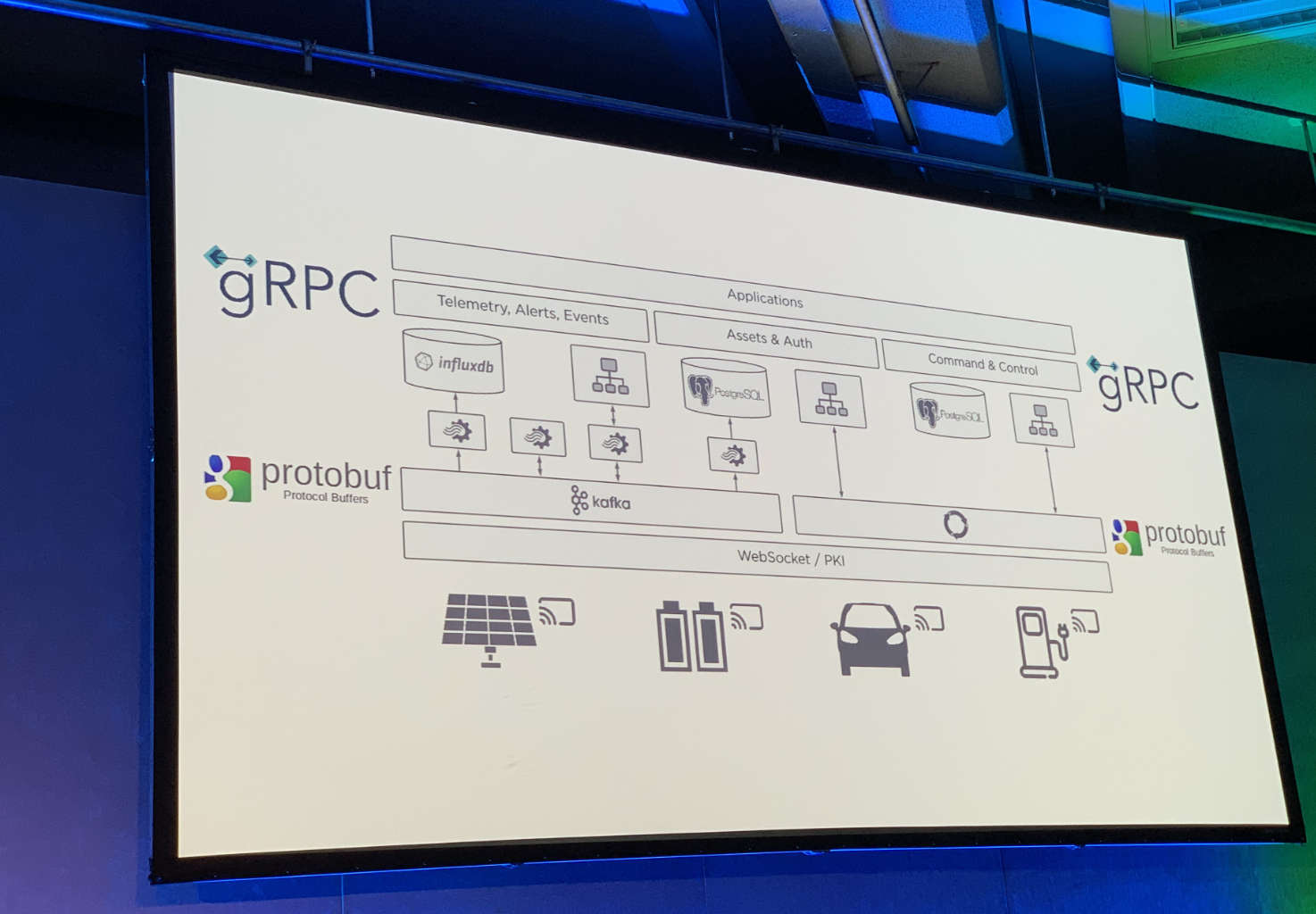
Tech stack for the Tesla Virtual Power Plant.
Optimise for Time: Andy Walker gave a great talk on Building High Performing Teams. It is probably my favorite “engineering culture” talk to date from a management perspective. Back when Andy was part of Google’s famous “Project Aristotle” (research on what makes effective teams) he noticed that teams that were really high-performing seemed to have more time than everybody else: they never hurried and always hit their deadlines, while teams that were struggling never had enough time and always felt behind and under pressure. The way the teams thought about time seemed to be the key factor. Andy offers some (ruthless) practical advice on how to get the most out of your time.
The End of the IT Manager – Being a Tech Lead in a Modern Organisation: Marcin Pakulnicki, ex-Chapter Lead and now Tribe Lead at ING Bank, explains how ING in 2016 implemented an agile transformation inspired by Spotify’s organizational model (squads and chapters). In ING they hold chapter meetings once a week for 3-4 hours to work on short-lived tech projects, which encourages innovation and knowledge transfer across squads. Chapter members are judged on results in chapter projects. The chapter lead’s job is about tech leadership as well as people skills, coaching, mentoring, working in a squad, recruiting, handling HR tasks, running the chapter meetings and managing chapter projects.
The Apollo Mindset: Making Mission Impossible, Possible: Richard Wiseman delivered an amazing closing keynote: the story of NASA’s Apollo program from the perspective of psychology and leadership, which is the subject of his book “Moonshot: What Landing a Man on the Moon Teaches Us About Collaboration, Creativity, and the Mind-set for Success”. Of course, the key takeaway is that seemingly impossible goals can be achieved if we approach them “one step at a time”. But what struck me most was the story of how NASA recruited mission controllers for the Apollo program. They could not recruit internally because their senior staff thought the mission was impossible. So they hired young people, from modest backgrounds, selected on passion and humility (good team players). Can you guess the average age of mission controllers at the start of the Apollo program?

21-year-old mission controllers: so young they didn’t know it couldn’t be done.
Memorable Quotes
- “Legacy is the cost of success” — Crystal Hirschorn
- “Constraints Liberate, Liberties Constrain” — Rúnar Bjarnason
- “APIs are the products of the 21st Century” — Paul Fremantle
Conclusion
The first image that pops in my mind when I think back about QCon London 2020 are hand sanitizers. In second place: images of NASA’s Apollo program—which were included in many talks, in addition to the closing keynote. I will also remember the fire alarm that forced the whole conference to evacuate the QEII Centre in the middle of the talks. Luckily, there was no fire, so it turned into a fun experience.
This was QCon’s 14th year in London. It was the best conference organization I have experienced in Europe so far. InfoQ has been organizing QCons across the globe for many years and all editions seem to be managed by the same core team, so I expect all editions to be well organized. On the other hand, speaker quality may vary a lot between editions, and some attendees did mention they thought the speakers were stronger in QCon SF when they attended. Nevertheless, the quality was first-class and I would be happy to return. I will also consider attending a US edition of QCon.
By sheer coincidence, 2020 is also the first year QCon is coming to Munich. It will be just after Oktoberfest—if large gatherings of people are allowed again, which currently seems unlikely. With hindsight, perhaps I should have attended the Leading Distributed Teams track this year. I completely skipped it, and one week later the whole world started to work remotely. Oh, the irony.